फ़ॉर्मेटिंग खोए बिना PDF का अनुवाद कैसे करें (2026 गाइड)
PDF का अनुवाद करते समय पढ़ने के क्रम, तालिकाओं, चार्ट, फ़ॉन्ट, RTL पाठ और पेज लेआउट को सुरक्षित रखने के लिए पुनरुत्पाद्य PDF स्ट्रेस टेस्ट का उपयोग करें।
त्वरित उत्तर: दस्तावेज़ की अर्थपूर्ण संरचना सुरक्षित रखें, हर निर्देशांक नहीं
फ़ॉर्मेटिंग खोए बिना PDF का अनुवाद करने के लिए, पहले यह निर्धारित करें कि उसमें चयनयोग्य टेक्स्ट, स्कैन की गई छवियाँ हैं, या दोनों। फिर पूरी फ़ाइल प्रोसेस करने से पहले लेआउट-सचेत PDF अनुवादक के साथ सबसे कठिन प्रतिनिधि पेज का परीक्षण करें। पढ़ने का क्रम, टेक्स्ट ओवरफ़्लो, तालिकाएँ, चार्ट लेबल, फुटनोट, फ़ॉन्ट और दाएँ-से-बाएँ पाठ की अलग-अलग समीक्षा करें।
लक्ष्य पिक्सेल-टू-पिक्सेल समानता नहीं है। अनुवाद में लाइन ब्रेक बदल सकता है या एक अतिरिक्त पेज जुड़ सकता है, और फिर भी दस्तावेज़ सही तरह से सुरक्षित रह सकता है। यह तब विफल होता है जब जानकारी गायब हो जाए, गलत तालिका पंक्ति में चली जाए, अपठनीय बन जाए, या किसी कैप्शन, फुटनोट, या दृश्य तत्व से उसका संबंध टूट जाए।
शुरुआती बिंदु के रूप में इस निर्णय तालिका का उपयोग करें:
| आपके पास मौजूद PDF | पहला कदम | मुख्य फ़ॉर्मेटिंग जोखिम |
|---|---|---|
| चयनयोग्य डिजिटल PDF | एक कठिन पेज का सीधे अनुवाद करें | पढ़ने का क्रम और टेक्स्ट-बॉक्स ओवरफ़्लो |
| स्कैन किया गया या फ़ोटो लिया गया PDF | OCR चलाएँ, टेक्स्ट लेयर की समीक्षा करें, फिर अनुवाद करें | OCR त्रुटियों का अनुवाद त्रुटियों में बदल जाना |
| घनी तालिकाओं या चार्ट वाला PDF | मर्ज की गई कोशिकाओं, संख्याओं और लेबल वाले पेज का परीक्षण करें | सही दिखने वाला लेआउट लेकिन गलत डेटा-संबंध |
| दो-कॉलम वाला शोध-पत्र या रिपोर्ट | प्रवाह का मूल्यांकन करने से पहले एक्सट्रैक्शन और पढ़ने का क्रम जाँचें | कॉलम का मिल जाना या पैराग्राफ़ का क्रम से बाहर अनुवाद होना |
| फ़ॉर्म, प्रमाणपत्र, या स्थिर टेम्पलेट | तय करें कौन-से निर्देशांक और पेज संदर्भ कानूनी या परिचालन रूप से स्थिर हैं | कठोर टेक्स्ट क्षेत्रों के कारण क्लिपिंग |
| द्विभाषी समीक्षा प्रति | साथ-साथ, इंटरलीव्ड, आमने-सामने पेज, या सिंक्रोनाइज़्ड फ़ाइलें चुनें | संकरे कॉलम और अस्थिर स्रोत-लक्ष्य संरेखण |
यह PDF अनुवाद श्रेणी के लिए केंद्रीय वर्कफ़्लो है। यदि आप फ़ाइल की जाँच के बजाय उत्पादों के बीच चयन कर रहे हैं, तो PDF अनुवादक तुलना से शुरू करें। यदि आप कोई टेक्स्ट चुन ही नहीं सकते, तो सीधे स्कैन किए गए PDF और OCR वर्कफ़्लो पर जाएँ।
“Keep Formatting” का वास्तव में क्या अर्थ होना चाहिए
फ़ॉर्मेटिंग संरक्षण कोई एकल पास/फ़ेल विशेषता नहीं है। इसकी कम से कम पाँच परतें हैं:
- सामग्री की पूर्णता: हर अर्थपूर्ण पैराग्राफ़, लेबल, चेतावनी, संख्या और नोट मौजूद रहना चाहिए।
- तार्किक संरचना: शीर्षक, सूचियाँ, तालिका कोशिकाएँ, कैप्शन, फुटनोट और पढ़ने का क्रम वही संबंध व्यक्त करें।
- दृश्य पदानुक्रम: शीर्षक अब भी शीर्षकों जैसे दिखें, कैप्शन अधीनस्थ रहें, और संबंधित वस्तुएँ समूहित रहें।
- लिपि समर्थन: चुने गए फ़ॉन्ट में लक्ष्य ग्लिफ़ मौजूद हों, और दिशा तथा विराम चिह्न सही रेंडर हों।
- पेज उपयोगिता: परिणाम सामान्य आकार पर बिना क्लिपिंग, ओवरलैप, या अंधाधुंध फ़ॉन्ट-छोटा करने के पठनीय रहे।
Adobe का PDF प्रलेखन दृश्यमान पेज सामग्री को ऑब्जेक्ट और मार्किंग ऑपरेशन की सूची के रूप में वर्णित करता है, Word-जैसे संपादनयोग्य पैराग्राफ़ अनुक्रम के रूप में नहीं। यह दस्तावेज़ की तार्किक संरचना और उसकी दृश्य स्थिति के बीच भी अंतर करता है। यही अंतर समझाता है कि कोई PDF सही दिख सकती है जबकि कॉपी किया गया टेक्स्ट, अभिगम्यता क्रम, या अनुवाद क्रम गलत हो। Adobe के PDF पेज सामग्री और टैग किए गए PDF में तार्किक संरचना. पर प्रलेखन देखें।
व्यावहारिक नियम सरल है: अनूदित दस्तावेज़ की तुलना केवल स्क्रीनशॉट के आधार पर नहीं, बल्कि संबंधों के स्तर पर करें।
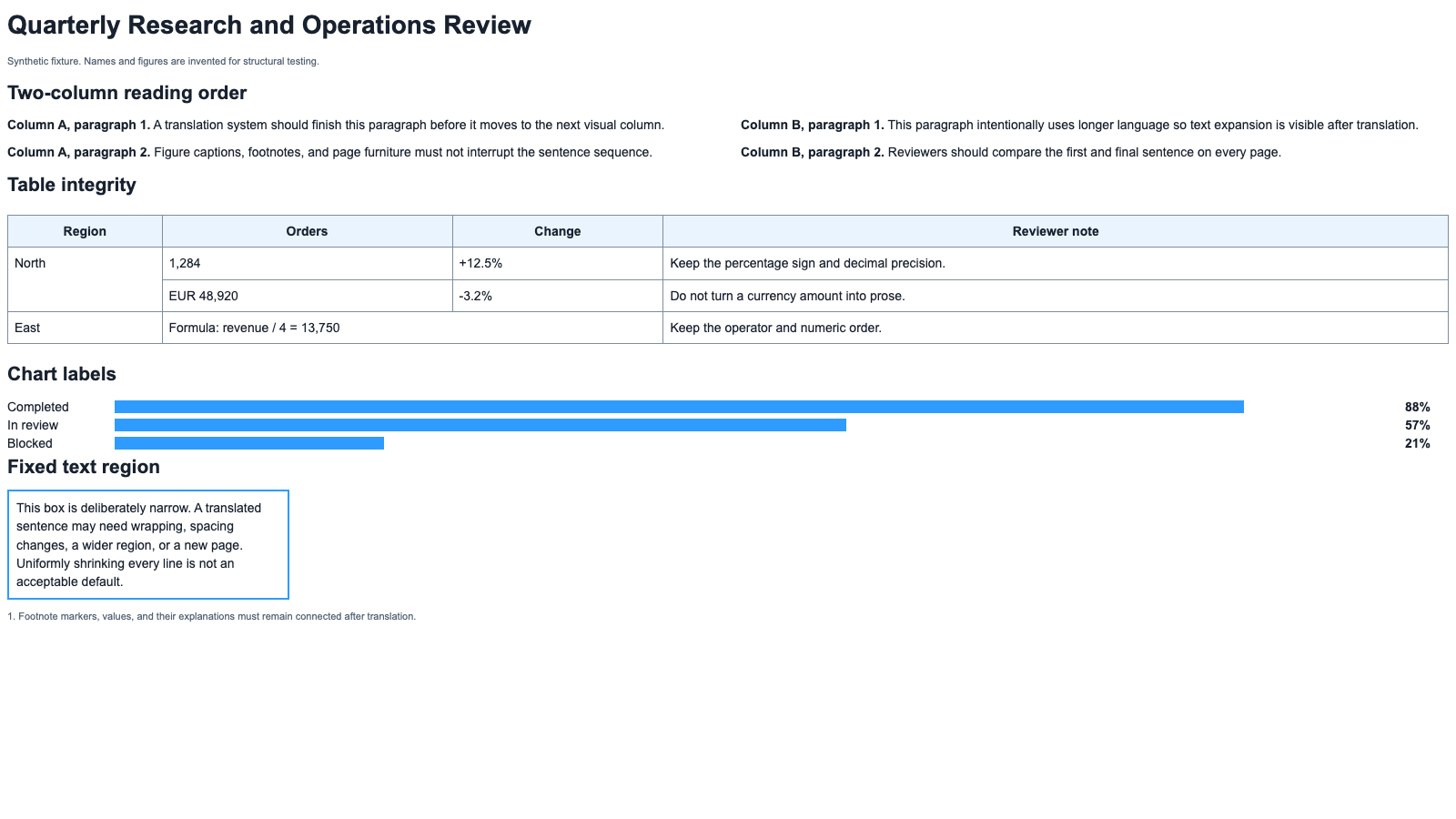
एक पुनरुत्पाद्य PDF लेआउट स्ट्रेस टेस्ट
हमने ग्राहक दस्तावेज़ों के बिना PDF के कठिन हिस्सों का परीक्षण करने के लिए दो-पेज का सिंथेटिक PDF लेआउट अनुवाद स्ट्रेस टेस्ट बनाया है। यह एक A4, टैग किया गया PDF है जिसमें काल्पनिक नाम और आँकड़े हैं। यह एक फ़िक्स्चर है, vendor benchmark नहीं, और न ही इस बात का प्रमाण कि कोई भी टूल सटीक अनुवाद देता है।
पेज 1 इन बातों का परीक्षण करता है:
- दो-कॉलम पढ़ने का क्रम;
- मर्ज की गई कोशिका वाली एक तालिका;
- एक पूर्णांक, मुद्रा राशि, चिह्नित प्रतिशत, और सूत्र;
- ऐसे चार्ट लेबल जिनकी स्थिति अर्थ वहन करती है;
- जानबूझकर संकरा रखा गया स्थिर टेक्स्ट क्षेत्र;
- ऐसा फुटनोट जिसे अपने marker से जुड़ा रहना चाहिए।
पेज 2 समान आकार के बॉक्सों के भीतर English, German, Chinese, और Arabic टेक्स्ट रखता है। यह चार अलग समस्याएँ उजागर करता है: स्थानीय विस्तार, लाइन रैपिंग, अनुपस्थित ग्लिफ़, और द्विदिश लेआउट।
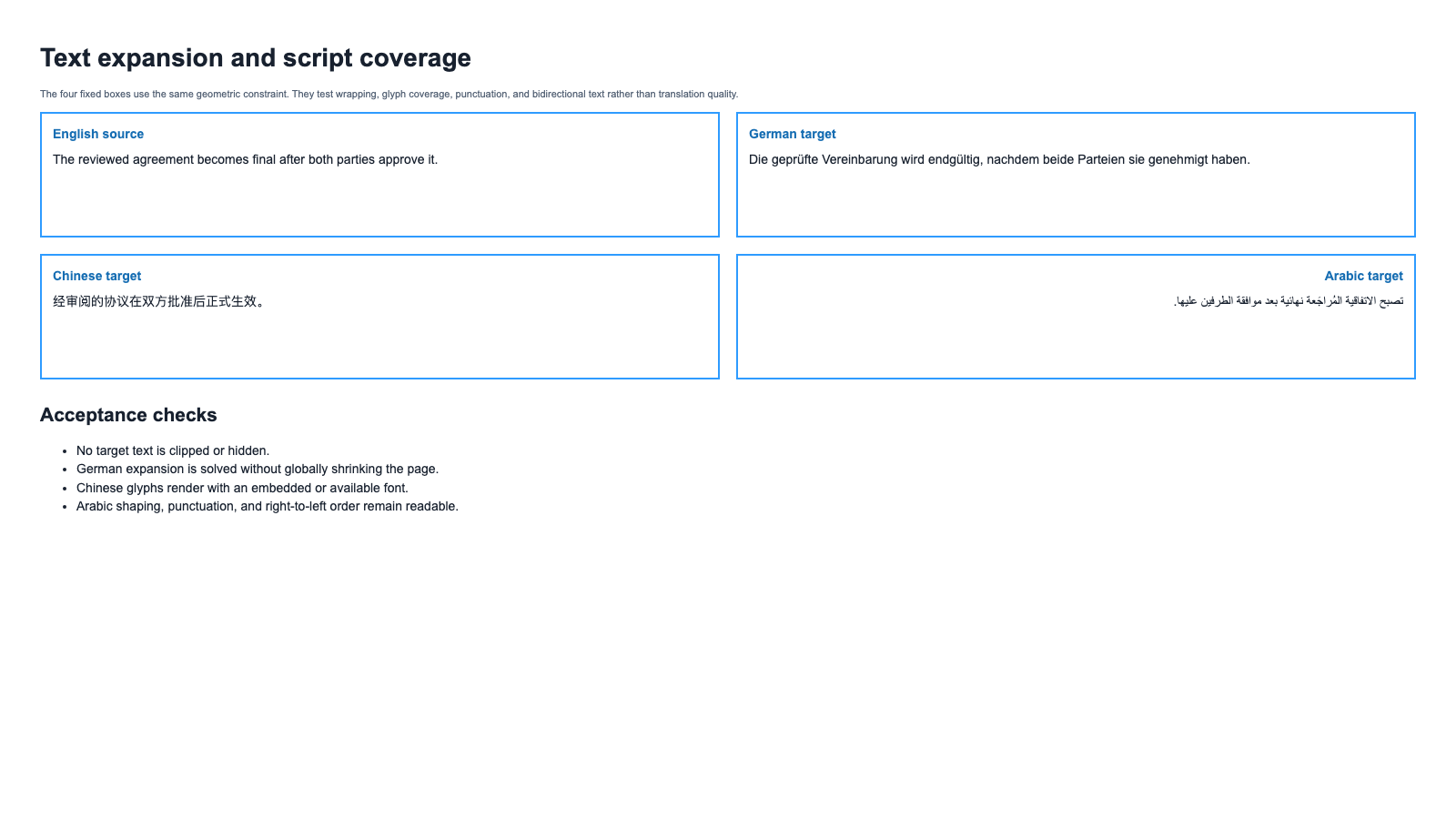
W3C की अनुवाद में टेक्स्ट आकार संबंधी मार्गदर्शिका बताती है कि छोटे लेबल और कड़े बंधन वाले क्षेत्र असंगत रूप से फैल सकते हैं, जबकि अन्य अनुवाद सिकुड़ भी सकते हैं। Unicode का द्विदिश एल्गोरिद्म निर्दिष्ट करता है कि मिश्रित बाएँ-से-दाएँ और दाएँ-से-बाएँ अक्षरों का समाधान कैसे किया जाता है। इन दोनों समस्याओं का भरोसेमंद समाधान केवल स्रोत अक्षरों की गिनती से नहीं हो सकता।
फ़िक्स्चर डाउनलोड करें और जिस भी वर्कफ़्लो पर आप विचार कर रहे हों उसमें इसे चलाएँ। टूल, तारीख, सेटिंग, स्रोत भाषा, लक्ष्य भाषा और आउटपुट फ़ाइल रिकॉर्ड करें। इससे “फ़ॉर्मेटिंग ठीक लग रही है” एक दोहराने योग्य परीक्षण में बदल जाता है।
अनुवाद से पहले अपने PDF का निदान करें
1. जाँचें कि टेक्स्ट चयनयोग्य है या नहीं
एक वाक्य और एक तालिका कोशिका चुनने की कोशिश करें।
- यदि दोनों साफ़-सुथरे ढंग से चुने जाते हैं, तो PDF में शायद उपयोगी टेक्स्ट लेयर है।
- यदि पूरा पेज एक ही छवि की तरह चुना जाता है, तो उसे OCR की आवश्यकता है।
- यदि टेक्स्ट बहुत छोटे टुकड़ों में चुना जाता है या कॉपी की गई पंक्तियाँ गलत क्रम में आती हैं, तो दृश्य स्थिति और तार्किक संरचना एक ही चीज़ नहीं हैं।
Adobe बताता है कि scanned PDF में शुरुआत में searchable text के बजाय image data होता है। OCR एक चयनयोग्य, खोजयोग्य layer जोड़ता है, लेकिन Adobe प्रोसेसिंग के बाद recognition errors की समीक्षा करने की भी सलाह देता है। देखें स्कैन किए गए PDF में टेक्स्ट पहचानें.
2. कठिन सेक्शन को सादा-पाठ संपादक में कॉपी करें
यह काम दो-कॉलम पैराग्राफ़, एक पूरी तालिका पंक्ति, और एक कैप्शन के साथ करें। यदि अनुवाद से पहले चिपकाया गया क्रम गलत है, तो अनुवाद लेयर गलत अनुक्रम से शुरू कर रही है।
Adobe का पठन क्रम टूल प्रलेखन दिखाता है कि जटिल तालिकाओं, चित्रों, बहुत पास-पास स्थित स्तंभों और पृष्ठ तत्वों के लिए स्पष्ट क्रम और टैगिंग मरम्मत की आवश्यकता हो सकती है। यदि कोई पैराग्राफ़ गलत टुकड़ों से बना है, तो प्रवाह उसे ठीक नहीं कर सकता।
3. सबसे कठिन प्रतिनिधि पेज चुनें
शीर्षक पेज का परीक्षण मत करें। वह पेज चुनें जिसके विफल होने की सबसे अधिक संभावना हो:
- सबसे घनी तालिका;
- सबसे संकरी साइडबार या कॉलआउट;
- फुटनोट वाला दो-कॉलम पेज;
- छोटे लेबल वाला चार्ट;
- CJK, Arabic, Devanagari, या मिश्रित लिपियों वाला पेज;
- कम contrast या skew वाला scan.
यदि सबसे कठिन पेज विफल होता है, तो पहले 200 आसान पेजों का अनुवाद करना केवल और अधिक सफ़ाई का काम पैदा करता है।
4. गैर-समझौतायोग्य बाधाएँ दर्ज करें
अलग-अलग दस्तावेज़ों में “सुरक्षित” की परिभाषा अलग होती है।
| दस्तावेज़ प्रकार | आम तौर पर गैर-समझौतायोग्य | आम तौर पर लचीला |
|---|---|---|
| अनुबंध या फ़ॉर्म | क्लॉज़ की पूर्णता, लेबल, हस्ताक्षर, पेज संदर्भ | स्थानीय रैपिंग और मामूली स्पेसिंग बदलाव |
| अकादमिक शोध-पत्र | समीकरण, उद्धरण, आकृति संबंध, पढ़ने का क्रम | पेज संख्या और पैराग्राफ़ लाइन ब्रेक |
| वार्षिक रिपोर्ट | संख्याएँ, इकाइयाँ, तालिका पंक्तियाँ, चार्ट संबंध | लेबल रैपिंग और स्थानीय क्षेत्र आकार |
| मैनुअल | चेतावनियाँ, चरण क्रम, कॉलआउट, छवि संदर्भ | पेजिनेशन और नियंत्रित रीफ़्लो |
| पुस्तक या लंबी रिपोर्ट | अध्याय क्रम, शीर्षक, नोट, छवि स्थान | पेज संख्या और पैराग्राफ़ प्रवाह |
मरम्मत चुनने से पहले इन बाधाओं को लिख लें। वरना समीक्षक अक्सर दृश्य समानता बचाने लगते हैं, भले ही उससे अर्थ को क्षति पहुँचे।
सबसे सुरक्षित एंड-टू-एंड वर्कफ़्लो
चरण 1: स्रोत सुरक्षित रखें और baseline स्थापित करें
एक untouched source file सुरक्षित रखें। पेज संख्या, फ़ाइल प्रकार, भाषा, PDF टैग किया गया है या नहीं, और टेक्स्ट चयनयोग्य है या नहीं, यह दर्ज करें। यदि दस्तावेज़ बाद में अपडेट होना है, तो PDF के साथ मूल source document भी सुरक्षित रखें।
चरण 2: OCR केवल आवश्यकता होने पर चलाएँ
केवल-छवि वाले पेजों के लिए सही स्रोत भाषा में OCR चलाएँ। अनुवाद से पहले नाम, संख्याएँ, विराम चिह्न, तालिकाएँ, फुटनोट और कम-कॉन्ट्रास्ट क्षेत्रों की समीक्षा करें। OCR त्रुटियाँ अपस्ट्रीम त्रुटियाँ होती हैं: यदि टेक्स्ट गलत पहचाना गया हो तो translation system उससे भी प्रवाहपूर्ण आउटपुट बना सकता है।
समर्पित स्कैन किए गए PDF गाइड में स्कैन सफ़ाई, OCR भाषा चयन, संदिग्ध अक्षर और गोपनीयता जाँच को अधिक विस्तार से समझाया गया है।
चरण 3: प्रतिनिधि पेज का अनुवाद करें
ऐसा वर्कफ़्लो उपयोग करें जो केवल अनूदित गद्य नहीं, बल्कि पूरा दस्तावेज़ लौटाने के लिए बनाया गया हो। अधिकांश फ़ॉर्मेटेड PDF के लिए इसका अर्थ है test file को BookTranslator PDF Translator पर अपलोड करना, language pair चुनना, और लौटाई गई PDF की समीक्षा करना।
केवल सबसे आसान पैराग्राफ़ का मूल्यांकन न करें। अपनी baseline में सूचीबद्ध सटीक तत्वों की तुलना करें।
चरण 4: शब्दों से पहले संरचना की समीक्षा करें
इस क्रम में जाँचें:
- क्या सभी source regions शामिल किए गए?
- क्या पढ़ने का क्रम सही है?
- क्या तालिका पंक्तियाँ, चार्ट लेबल, कैप्शन और फुटनोट अब भी सही वस्तुओं की ओर संकेत कर रहे हैं?
- क्या संख्याएँ, नाम, इकाइयाँ और सूत्र सुरक्षित हैं?
- क्या लक्ष्य लिपि सही रेंडर हो रही है?
- केवल उसके बाद: क्या अनुवाद प्रवाहपूर्ण और सटीक है?
गलत टेक्स्ट क्रम का चमकदार अनुवाद भी विफल दस्तावेज़ ही है।
चरण 5: पूरी फ़ाइल का अनुवाद करें और जोखिमपूर्ण पेजों के नमूने जाँचें
प्रतिनिधि पेज के पास होने के बाद पूरी PDF का अनुवाद करें। केवल पहला पेज जाँचने के बजाय हर जोखिमपूर्ण संरचना की पहली, बीच की, और आख़िरी घटना की समीक्षा करें।
एक लंबी रिपोर्ट के लिए इसका अर्थ हो सकता है:
- पहला और आख़िरी दो-कॉलम पेज;
- सबसे सरल और सबसे घनी तालिका;
- शुरुआत और अंत के पास का एक-एक चार्ट;
- हर चेतावनी पेज;
- हर वह पेज जहाँ लक्ष्य लिपि या फ़ॉन्ट बदलता है।
चरण 6: सबसे कम विनाशकारी मरम्मत लागू करें
स्थानीय समस्या को स्थानीय रूप से ठीक करें। केवल एक शीर्षक लंबा है, इसलिए पूरे दस्तावेज़ को वैश्विक रूप से छोटा मत करें।
सब कुछ छोटा किए बिना टेक्स्ट ओवरफ़्लो ठीक करें
अनूदित टेक्स्ट तब ओवरफ़्लो करता है जब लक्ष्य शब्दावली अब स्रोत क्षेत्र की ज्यामिति में फिट नहीं बैठती। तात्कालिक कारण टेक्स्ट विस्तार हो सकता है, लेकिन बाध्यकारी सीमा आमतौर पर कोई एक विशिष्ट बॉक्स, कॉलम, पंक्ति, फ़ॉन्ट, या लाइन-ब्रेकिंग नियम होता है।
मरम्मत इस क्रम में लागू करें:
| क्रम | मरम्मत | कब उपयोग करें | मुख्य जोखिम |
|---|---|---|---|
| 1 | प्राकृतिक रैपिंग की अनुमति दें | क्षेत्र में अप्रयुक्त ऊर्ध्वाधर स्थान हो | सूची इंडेंटेशन या पंक्ति ऊँचाई बदल सकती है |
| 2 | स्थानीय लाइन या पैराग्राफ़ स्पेसिंग समायोजित करें | ओवरफ़्लो छोटा हो | घना टेक्स्ट पढ़ना कठिन हो सकता है |
| 3 | प्रभावित क्षेत्र को चौड़ा या बड़ा करें | आसपास की खाली जगह वास्तव में अप्रयुक्त हो | पास की वस्तुएँ खिसक सकती हैं |
| 4 | आसपास के तत्वों का रीफ़्लो करें | कई ब्लॉक जगह के लिए प्रतिस्पर्धा करें | पेज पदानुक्रम और संदर्भ भटक सकते हैं |
| 5 | स्वीकृत छोटा लक्ष्य पद उपयोग करें | मानक संक्षिप्त शब्द उपलब्ध हो | अर्थ के लिए द्विभाषी समीक्षा चाहिए |
| 6 | continuation page जोड़ें | सामग्री पठनीय रूप से फिट न हो सके | पेजिनेशन बदलता है |
| 7 | स्थानीय रूप से फ़ॉन्ट आकार घटाएँ | हल्की कमी भी पठनीय रहे | अभिगम्यता और दृश्य संगति |
किसी एक भाषा-विस्तार प्रतिशत पर निर्भर मत रहें। कोई German पैराग्राफ़ फिट हो सकता है जबकि संयुक्त शीर्षक विफल हो जाए। Chinese गद्य सिकुड़ सकता है जबकि अनूदित न किया गया URL फिर भी किसी कोशिका से बाहर निकल जाए। Arabic अक्षर-गणना से फिट लग सकती है लेकिन फ़ॉन्ट, shaping, punctuation, या direction गलत होने से विफल हो सकती है।
यह निदान उपयोग करें:
- एक बॉक्स में क्लिप हुआ: उस क्षेत्र का आकार बदलें या रीफ़्लो करें।
- बॉक्स दिखाई दें या अक्षर गायब हों: आवश्यक ग्लिफ़ वाला फ़ॉन्ट बदलें या एम्बेड करें।
- लंबे शब्द या URLs रैप होने से इंकार करें: लाइन-ब्रेकिंग या हाइफ़नेशन नियम ठीक करें।
- केवल तालिका शीर्षक विफल हों: तालिका-विशिष्ट मरम्मत उपयोग करें।
- हर पेज पर दोहराए जाने वाले शीर्षक टकराएँ: हर पैराग्राफ़ के बजाय पेज टेम्पलेट संशोधित करें।
- दो टुकड़े मिलकर एक बहुत बड़ा पैराग्राफ़ बन जाएँ: टाइपोग्राफ़ी छूने से पहले पढ़ने का क्रम ठीक करें।
यदि स्रोत लेआउट में लक्ष्य भाषा के विश्वसनीय संस्करण के लिए जगह ही नहीं है, तो समान निर्देशांक गलत स्वीकृति मानदंड हैं। इसके बजाय पूर्णता, पदानुक्रम और पठनीयता सुरक्षित रखें।
तालिकाएँ, चार्ट, संख्याएँ और फुटनोट सुरक्षित रखें
PDF तालिका हमेशा तालिका के रूप में संग्रहीत नहीं होती। वह ग्रिड लाइनों के ऊपर संपादनयोग्य टेक्स्ट हो सकती है, कई स्थित खंड हो सकते हैं, या एकल छवि हो सकती है। चार्ट लेबल अलग टेक्स्ट हो सकता है या ग्राफ़िक में स्थायी रूप से समाहित हो सकता है।
इससे विफलता की चार स्वतंत्र श्रेणियाँ बनती हैं:
| विफलता श्रेणी | उदाहरण | केवल दृश्य निरीक्षण इसे क्यों चूक जाता है |
|---|---|---|
| संरचनात्मक | कोई मर्ज की गई कोशिका टूट जाए या दो कोशिकाएँ एक वाक्य बन जाएँ | परिणाम फिर भी aligned दिख सकता है |
| संख्यात्मक | -3.2% से minus sign गायब हो जाए या दूसरी पंक्ति में चला जाए | प्रवाहपूर्ण गद्य मान से ध्यान हटा देता है |
| दृश्य | अनूदित शीर्षक सीमा रेखा को पार कर जाए | टेक्स्ट फिर भी पूर्ण हो सकता है |
| संदर्भात्मक | फुटनोट marker अपनी note खो दे | दोनों हिस्से कहीं और अब भी दिख सकते हैं |
इनके लिए संरक्षित-टोकन समीक्षा उपयोग करें:
- पूर्णांक और दशमलव मान;
- धनात्मक और ऋणात्मक चिह्न;
- प्रतिशत, मुद्राएँ, तिथियाँ और संस्करण संख्याएँ;
- इकाइयाँ और सूत्र;
- तालिका और आकृति संख्याएँ;
- फुटनोट marker और उनका व्याख्यात्मक टेक्स्ट।
locale conventions दशमलव विभाजक या मुद्रा-स्थान बदल सकती हैं। प्रश्न यह नहीं है कि हर अक्षर समान है या नहीं; प्रश्न यह है कि क्या लक्ष्य वही मात्रा व्यक्त करता है और सही लेबल से जुड़ा रहता है।
हर तालिका के लिए सत्यापित करें:
- पंक्तियों और कॉलम की संख्या अब भी मेल खाती है।
- मर्ज की गई कोशिकाएँ वही records कवर करती हैं।
- हर संख्या अपने स्रोत लेबल के साथ जोड़ी हुई रहती है।
- इकाइयाँ, चिह्न और परिशुद्धता सही हैं।
- फुटनोट अब भी इच्छित मान को qualify करते हैं।
- शीर्षक रैपिंग ने सामग्री नहीं छिपाई है।
हर चार्ट के लिए सत्यापित करें कि ज्यामिति और डेटा अपरिवर्तित हैं, लेबल अब भी सही दृश्य चिह्नों की पहचान करते हैं, और कैप्शन जुड़े रहते हैं। यदि लेबल किसी image में embedded हैं, तो image-aware OCR का उपयोग करें और उन्हें फिर से बनाएँ, या translated caption या legend के साथ मूल chart बनाए रखें। लंबे लेबल फिट करने के लिए chart को stretch या crop मत करें।
यदि किसी वित्तीय, वैज्ञानिक, या कानूनी तालिका में एक भी मान-संबंध गलत है, तो दस्तावेज़ विफल है, चाहे वह कितना भी polished क्यों न दिखे।
एक द्विभाषी PDF लेआउट चुनें
द्विभाषी PDF तब उपयोगी होती है जब किसी को लक्ष्य पाठ की स्रोत से तुलना करके जाँच करनी हो। यह अपने-आप सबसे अच्छा अंतिम deliverable नहीं बन जाती।
| समीक्षा कार्य | सबसे अच्छा शुरुआती लेआउट | समझौता |
|---|---|---|
| पैराग्राफ़-दर-पैराग्राफ़ संपादन | स्रोत बाएँ, लक्ष्य दाएँ | संकरे कॉलम ओवरफ़्लो बढ़ा देते हैं |
| मोबाइल या टैबलेट अध्ययन | स्रोत पैराग्राफ़ के बाद लक्ष्य पैराग्राफ़ | पेज संख्या बढ़ती है |
| कानूनी या अभिलेखी संदर्भ | आमने-सामने स्रोत और लक्ष्य पेज | दस्तावेज़ की लंबाई लगभग दोगुनी हो जाती है |
| घनी तालिकाएँ और स्थिर पेज | अलग लेकिन सिंक्रोनाइज़्ड स्रोत और लक्ष्य PDF | ऐसा viewer या review process चाहिए जो पेजों को aligned रखे |
| क्लाइंट डिलीवरी | केवल-लक्ष्य PDF और अलग द्विभाषी समीक्षा प्रति | दो नियंत्रित फ़ाइलें बनाए रखनी पड़ती हैं |
दृश्य लाइन ब्रेक के आधार पर alignment मत करें। अनुवाद एक source sentence को दो target sentence में बाँट सकता है या दो छोटे sentence को जोड़ सकता है। शीर्षक, पैराग्राफ़ क्रम, तालिका संख्याएँ, आकृति संख्याएँ, सूची आइटम और फुटनोट marker को स्थिर anchor की तरह उपयोग करें।
जब स्रोत में पहले से कई कॉलम, घनी तालिकाएँ, हाशिये के नोट, या बड़ा स्थानीय विस्तार हो, तब side-by-side खराब default है। ऐसे मामलों में आमने-सामने पेज या सिंक्रोनाइज़्ड एकभाषी फ़ाइलें सामान्य पठन-चौड़ाई बनाए रखती हैं और विफलताओं को अलग करना आसान बनाती हैं।
जहाँ संभव हो, दोनों भाषाएँ searchable और selectable रहनी चाहिएँ। कॉपी किए गए टेक्स्ट क्रम, दस्तावेज़ भाषा metadata, शीर्षक, table tags, और figure descriptions जाँचें। यदि accessibility कठोर आवश्यकता है, तो जटिल alternating-column संरचना की तुलना में अलग एकभाषी फ़ाइलें अक्सर अधिक सुरक्षित होती हैं।
काम के लिए सही टूल चुनें
समर्पित PDF अनुवादक
लंबी, फ़ॉर्मेटेड, या client-facing PDF के लिए समर्पित अनुवादक उपयोग करें। जब अपेक्षित आउटपुट text transcript के बजाय दूसरी उपयोगी PDF हो, तब यही सही शुरुआती बिंदु है।
Google Translate
छोटे, सरल दस्तावेज़ों की त्वरित समझ के लिए Google Translate उपयोग करें, जब लेआउट स्वयं अंतिम सुपुर्दगी न हो। बहु-कॉलम पेज, स्कैन, घनी तालिकाएँ और अंतिम प्रकाशन के लिए अधिक नियंत्रित वर्कफ़्लो चाहिए। Google Translate PDF गाइड इसका दस्तावेज़ वर्कफ़्लो और विफलता संकेत कवर करती है।
ChatGPT
छोटे अंशों, शब्दावली तैयारी, स्वर संबंधी निर्णयों और द्विभाषी समीक्षा के लिए ChatGPT उपयोग करें। लंबी PDF के लिए chat interface को page-layout engine मत मान लें। ChatGPT PDF वर्कफ़्लो में ऐसे prompts शामिल हैं जो summarization और added content को प्रतिबंधित करते हैं।
PDF को DOCX में बदलें
पहले conversion केवल तब करें जब आप दस्तावेज़ को manually edit या rebuild करना चाहते हों। conversion अनुवाद शुरू होने से पहले तालिकाएँ तोड़ सकता है, टुकड़ों का क्रम बदल सकता है, और chart labels को floating boxes में बदल सकता है। प्रतिबद्ध होने से पहले सबसे कठिन पेज का परीक्षण करें। यदि converted DOCX संरचनात्मक रूप से साफ़ है, तो DOCX अनुवादक के साथ आगे बढ़ें; यदि वह पहले से टूटा हुआ है, तो translation conversion को ठीक नहीं करेगी।
मानव या द्विभाषी समीक्षक
कानूनी, चिकित्सा, वित्तीय, सुरक्षा-महत्वपूर्ण, अकादमिक, या प्रकाशित सामग्री के लिए योग्य reviewer उपयोग करें। लेआउट वर्कफ़्लो हर बॉक्स सुरक्षित रख सकती है जबकि अर्थ फिर भी गलत हो सकता है। वास्तविक अनुवाद नमूने देखें, जहाँ हम language review और layout review को अलग रखते हैं।
PDF अनुवाद स्वीकृति चेकलिस्ट
अवरोधक समस्याएँ
- गायब या क्लिप किया गया टेक्स्ट
- गलत पढ़ने का क्रम
- ओवरलैप होते पैराग्राफ़ या लेबल
- गलत पंक्ति या चार्ट तत्व को सौंपे गए अंक
- बदले हुए सूत्र, चिह्न, इकाइयाँ, या संदर्भ
- अपठनीय फ़ॉन्ट आकार
- लक्ष्य भाषा के ग्लिफ़ का अभाव
- टूटी हुई Arabic या Hebrew दिशा और विराम चिह्न
- छिपी हुई चेतावनियाँ, कैप्शन, या फुटनोट
प्रमुख दोष
- अटपटी लेकिन पठनीय रैपिंग
- आकृतियों से अलग हुए कैप्शन
- बड़ा, अस्पष्टीकृत पेज विचलन
- शीर्षकों के साथ असंगत व्यवहार
- बार-बार स्थानीय फ़ॉन्ट-आकार बदलाव
- गलत स्रोत passage के साथ aligned द्विभाषी ब्लॉक
सजावटी अंतर
- अलग line endings
- whitespace में छोटे बदलाव
- संदर्भ ठीक होने पर पेज संख्या में मामूली बदलाव
- सभी सामग्री दृश्यमान होने पर तालिका पंक्ति ऊँचाइयों में हल्का अंतर
हर विफल पेज के लिए स्रोत पेज, तत्व प्रकार, लक्षण, बाध्यकारी प्रतिबंध, सुधार, और क्या द्विभाषी अर्थ समीक्षा आवश्यक है, यह दर्ज करें। यह ऑडिट ट्रेल “formatting adjusted” कहने से कहीं अधिक उपयोगी है।
अधिकांश PDF के लिए अनुशंसित वर्कफ़्लो
- untouched source PDF सुरक्षित रखें।
- जाँचें कि टेक्स्ट और तालिका कोशिकाएँ चयनयोग्य हैं या नहीं।
- केवल image-only content के लिए OCR चलाएँ, फिर recognition errors की समीक्षा करें।
- PDF स्ट्रेस टेस्ट डाउनलोड करें या अपनी फ़ाइल से सबसे कठिन पेज चुनें।
- उस प्रतिनिधि पेज का PDF Translator से अनुवाद करें।
- भाषा प्रवाह से पहले पढ़ने का क्रम, तालिकाएँ, संख्याएँ, लेबल, फुटनोट, फ़ॉन्ट और दिशा की समीक्षा करें।
- प्रतिनिधि पेज के पास होने के बाद ही पूरी फ़ाइल का अनुवाद करें।
- स्थानीय बाधाओं को स्थानीय रूप से ठीक करें; दस्तावेज़ को वैश्विक रूप से छोटा मत करें।
- भविष्य के revisions के लिए source, translated PDF, settings, glossary, और review notes को साथ रखें।
समीकरण, उद्धरण, और शोध लेआउट के लिए अकादमिक शोध-पत्र अनुवाद वर्कफ़्लो पर आगे बढ़ें। यदि आप अभी भी तय कर रहे हैं कि source PDF हो या EPUB, तो EPUB बनाम PDF निर्णय गाइड उपयोग करें।
FAQ
फ़ॉर्मेटिंग खोए बिना PDF का अनुवाद करने का सबसे अच्छा तरीका क्या है?
लेआउट-सचेत PDF अनुवादक के साथ एक कठिन प्रतिनिधि पेज का परीक्षण करें, फिर तार्किक संरचना और पेज लेआउट की अलग-अलग समीक्षा करें। चयनयोग्य PDF के लिए PDF Translator से शुरू करें। scanned PDF के लिए OCR चलाएँ और अनुवाद से पहले text layer सुधारें।
अनुवाद के दौरान PDF की फ़ॉर्मेटिंग क्यों टूट जाती है?
PDF पेजों में सरल संपादनयोग्य पैराग्राफ़ प्रवाह के बजाय स्थित ऑब्जेक्ट और ड्रॉइंग निर्देश होते हैं। अनुवाद टेक्स्ट लंबाई, रैपिंग, ग्लिफ़ मेट्रिक्स, और दिशा बदल देता है, इसलिए सिस्टम को तार्किक संबंधों और दृश्य स्थिति दोनों का पुनर्निर्माण करना पड़ता है।
क्या अनूदित PDF बिल्कुल वही पेज संख्या बनाए रख सकती है?
कभी-कभी, लेकिन एक जैसी पेजिनेशन को पूर्णता या पठनीयता पर हावी नहीं होना चाहिए। forms, contracts, और cited reports में सख्त page references की आवश्यकता हो सकती है; सामान्य reports और books references अपडेट होने पर सुरक्षित रूप से continuation page जोड़ सकते हैं।
ओवरफ़्लो करने वाले अनूदित टेक्स्ट को मुझे कैसे ठीक करना चाहिए?
प्राकृतिक रैपिंग, स्थानीय स्पेसिंग, प्रभावित क्षेत्र का आकार बदलना, नियंत्रित रीफ़्लो, स्वीकृत छोटा पद, या continuation page आज़माएँ, इसी क्रम में। फ़ॉन्ट आकार केवल स्थानीय रूप से और केवल तब घटाएँ जब वह पठनीय बना रहे।
क्या PDF अनुवादक तालिकाएँ और चार्ट सुरक्षित रख सकता है?
यह कई मूल-पाठ तालिकाएँ और संपादन योग्य लेबल सुरक्षित रख सकता है, लेकिन मर्ज किए गए सेल, स्थित खंड, स्कैन, और image-based charts के लिए अब भी स्पष्ट समीक्षा चाहिए। data integrity और layout integrity को अलग पास/फेल परीक्षणों की तरह जाँचें।
क्या मुझे side-by-side bilingual PDF बनानी चाहिए?
चौड़े, सरल पेजों पर paragraph review के लिए side-by-side columns उपयोग करें। मोबाइल पढ़ाई के लिए interleaved blocks, page-level reference के लिए facing pages, या dense layouts के लिए synchronized source और target PDF उपयोग करें। पहले से संकरे कॉलम में दो भाषाओं को जबरन मत ठूसें।
क्या Google Translate या ChatGPT PDF की फ़ॉर्मेटिंग सुरक्षित रख सकते हैं?
Google Translate त्वरित समझ के लिए उपयोगी हो सकता है, और ChatGPT passages, glossaries, और review में मदद कर सकता है। किसी जटिल अंतिम PDF को सुरक्षित रखने की उनकी क्षमता को परीक्षण के बिना मानकर न चलें। जब आउटपुट फ़ाइल और पेज संरचना महत्वपूर्ण हो, तब document-oriented workflow उपयोग करें।
अनूदित PDF में मुझे सबसे पहले क्या जाँचना चाहिए?
जाँचें कि हर source region मौजूद है और सही reading order में है। फिर तालिकाएँ, संख्याएँ, चार्ट लेबल, कैप्शन, फुटनोट, फ़ॉन्ट, और RTL text की जाँच करें। document structure पास होने के बाद ही fluency की समीक्षा करें।